A Personal History of Legion, by Way of Its Papers
The path to publication is rarely as linear as the publication record would appear to indicate. For the last 12 years, I have been an active contributor to Legion, a research project originally out of Stanford which aimed to create a programming system for supercomputers that fundamentally and dramatically simplifies the way we program these machines, while providing best-in-class performance and scalability. Through many years of hard work, I believe we have succeeded in this goal. But even so, these years have been anything but straightforward.
This document is a personal history of Legion: the story of the project, told through the lens of the papers we wrote about it, and the journey that brought us to each one.
In research, we rarely talk about the struggle involved in doing research. We especially don’t like to talk about rejection. I think this does the community a disservice by glossing over the challenges we face getting to the results that eventually do get published, trivializing the process and minimizing the (mundane but necessary) engineering work that makes the research possible in the first place—making the process seem simple and almost boring. The real story, is (you guessed it) anything but.
Almost every paper we published along the way was rejected at least once. A majority of papers were rejected multiple times. And some papers were rejected so much that they eventually landed back at the same conferences that initially rejected them. Contrary to what the cynics might say, these rejections made the papers stronger, clearer, and in some cases helped us clarify our own contributions in the work that we ultimately published. But of course that doesn’t mean that receiving those rejections was easy.
Legion is both a research project and also a living piece of software. So, while I focus here on papers about Legion, I could have equally written about the software itself. Sometimes, those paths lined up, and sometimes they diverged quite dramatically. For better or worse, not everything that is essential to maintaining a long-term software project leads to a publishable research article—something that I hope to remedy someday by writing a software history of Legion. But this is not that post.
Because this is a personal history, I am going to focus on the papers that I had the most direct involvement with. Therefore, this story doesn’t start quite at the beginning, because my involvement with the project began about 3–6 months after it had started. And there are many, important Legion papers that I won’t touch on due to my relative lack of involvement. There are certainly more stories that could be told, but others will have to tell them.
A Brief Overview of Legion
If you found your way here without knowing anything about Legion, Legion is a distributed, heterogeneous programming system for high-performance computing (HPC). The goal of Legion is to make it easy to program clusters of CPUs and GPUs (or in the future, whatever hardware we end up running in HPC). Legion’s core value proposition is that it is implicitly parallel, that is, users do not have to worry about the tedious, error-prone, low-level details of how their programs run on the hardware. Among systems with comparable goals, Legion is distinguished by having an exceptionally flexible data model, something that is our key advantage and has also been the biggest challenge in making the system work and scale well.
Legion (SC 2012)
I arrived at Stanford in 2011 for my Ph.D. program. First year students go through rotations, or temporary assignments with different professors, to get a feeling for research with various advisors. My second rotation was with Alex Aiken.
At the time Legion had just gotten off the ground, literally 3–6 months prior to my joining. I was entering almost (but not quite) on the ground floor. While the project itself was cool, what immediately sold me on it was the team. The two students running the project, Mike Bauer and Sean Treichler, were clearly driving the research and knew what they were doing. I was hooked.
My assignment in the beginning was nominally scaling. (Legion is a distributed programming system for HPC, so scaling means running a program on more nodes.) This was in retrospect a laughable goal—utterly ridiculous. The software I had access to didn’t run. Sometimes it didn’t even build. The applications for our experiments hadn’t even been written yet, and when I started to write one, the software immediately fell over.
And so my role evolved into that of a glorified tester. I would write code, build it, and one of two things would happen: either it wouldn’t build, or it would build but then crash. I would turn to Mike Bauer, who (in a stroke of blessed administrative competence) was sitting next to me, and report the bug. Fifteen minutes later he’d push a fix that would unblock me and I’d go back to coding until I hit the next issue. As I recall, in those early days I hit about one bug an hour, so somewhere between half a dozen to a dozen bugs a day.
Overall, I think this approach worked well. My being on the team allowed Mike to avoid thinking about testing at all in this early phase of the project, and just build. Because I was testing the code on a continuous basis, I usually found bugs within an hour of them being introduced. I was also kicking the tires of the API to make sure it was possible to write the necessary application code, which was also not always the case. In any event, splitting the responsibilities allowed each of us to iterate on our respective parts as fast as possible, and mostly without blocking each other.
We set a goal of sending the paper to SC 2012. Technically, this was the second submission for this paper, but both the software and the paper itself evolved so aggressively that there isn’t that much in common with the first submission. Alex Aiken, our advisor, took responsibility for the text of the paper, while the three students (Mike, Sean and myself) continued working full-time on the code, which was not ready until right before the deadline. As would become a trend for us, we finished our experiments at the last minute and squeaked in under the deadline.
As it turns out, we kept most of our papers under version control in a repository which has since been released to the public. Therefore, if you want to read any of our old papers (including submissions that were rejected), you can navigate to the corresponding source directory and type make.
Submission history:
Intermission: Partitioning (OOPSLA 2013) and Realm (PACT 2014)
My rotation ended and I went off to work with another professor for three months. While I would come back to work on Legion full-time after this, those three months were apparently a prolific time for the team because they managed to get off two paper submissions without me. Oof! These papers described a type system for Legion (focusing on data partitioning), and the low-level portability runtime Realm. Because I was away, I wasn’t really involved in these papers, so I won’t cover them in detail—but both went through a pretty long rejection cycle before finally finding a home.
Partitioning submission history:
Realm submission history:
- ASPLOS 2013: rejected. Source.
- PLDI 2013: rejected. Source.
- ASPLOS 2014: rejected. Source.
- PLDI 2014: rejected. Source.
- PACT 2014: accepted. Source, PDF.
Structure Slicing (SC 2014)
To no one’s surprise whatsoever, writing software under intense time pressure does not lead to high quality production software. And so the history of Legion is one of qualitative, often step-function improvements to the software, through repeated rewrites of the code. In our defense, this wasn’t just because of shoddy engineering (though the first couple of versions of Legion were definitely rushed). As it turned out, we dramatically underestimated the complexity of the original problem we were trying to solve, and as we peeled away the layers, we kept finding more and more complexity beneath. Realistically, if Legion had been a commercial project, this surely would have killed it after the first couple of rewrites. But since we were academics, each new twist in the road provided us an excuse to publish—which laid the foundations of several Ph.D. careers.
Structure slicing was the third complete rewrite of the Legion runtime, and the first that changed the conceptual model of the problem we were trying to solve. (Two previous rewrites had focused on paying down technical debt, and changing the runtime’s internal model of execution, but neither were user-facing.) The key observation that led us to structure slicing is that the user’s data frequently consists of objects with multiple fields. In any given task (or function), you might not need all of those fields. This might not make any significant difference in a classical system, but on distributed machines, you can save a huge amount of data movement (and thus greatly improve performance) by only moving the necessary fields. But to do so requires that Legion reason about those fields, which essentially adds an entire new dimension of complexity to the runtime.
My role in this paper was essentially the same as the last one: I prepared application codes for deployment with the updated runtime interfaces, and tested them aggressively to work out the bugs (of which there were many). But I was getting a bit restless and wanted to strike out on my own, which I’ll cover next.
This paper was also rejected once prior to acceptance, in what would become an ongoing trend for our research group. To this day, no core Legion technology paper has ever been accepted for publication to PLDI, the conference that we almost always submitted to first. Instead (and with no small irony), the first Legion paper ever accepted to PLDI was about a library running on top of Legion—a great paper, but one that would never have been possible at all if it hadn’t been for all the (rejected) papers that came before it.
In retrospect, it was for the best that this paper got rejected. In the four months between the first and second submissions, we got one of our codes to run on over 1024 nodes (and then, in the next six months, to the entirety of Titan, then the #1 supercomputer in the world). This was truly a dramatic improvement over our first paper, where our highest achieved node count was only 16.
But there was a catch: we were only able to do this for one application. And the application, as impressive as it was, had to be hand-written to use new features introduced specifically into Legion for the purpose of improving scalability. This code was notoriously difficult to write because it broke holes in the nice, implicitly parallel Legion abstraction that we’d worked so hard to promote. And so while technically, this was the first paper to present truly scalable Legion results, fixing the leaky abstraction would take us another three years.
Submission history:
Regent (SC 2015)
Legion is sort of an odd project. Technically, the software is written in C++. You can (and we did) use it from C++. In the early years of the project, this was how every Legion application was written. And yet, being the programming language geeks we were, we designed Legion to have a type system, and users were expected to follow those rules. By 2013 it was pretty obvious that writing proper Legion code in C++ was hard and that we needed to develop an actual language around the project.
At the tail-end of my second year as a Ph.D. student, I began to work on the language that would eventually become Regent. According to our Git repository history, the very first version of Regent was written in Haskell. To be honest, that version was so short-lived that I forgot (until I went to look) that it ever existed. For the next 12 months, the version of Regent that existed until just 10 months before the final paper submission, was written in Python. But the version that would eventually be published was written in a new language also developed at Stanford, called Terra.
There were three compelling features that drove me to adopt Terra:
- An extensible parser. Terra libraries can define new languages, and a simple but useful parser library is provided.
- Code generation. Terra exists for meta-programming, which is much easier than slapping together strings of C++ code (as my Python-based compiler had been doing).
- Easy access to C. Importing a C header file is literally a one-liner. This had been a major struggle for me when building my own Python compiler.
As you might expect, when you develop a compiler for the first time, it’s easy to generate really slow code. But the slowdown of the early versions of the Regent compiler were truly astonishing. My first application, developed during a summer internship at Los Alamos National Lab (LANL) in 2013, was a port of Pennant, itself a miniaturized version of a production hydro-shock simulation code used at the lab.
The initial version of Pennant in Regent was slower than the original code by a whopping factor of 10,000. Note: that wasn’t the distributed version of Pennant. It wasn’t even the multi-core version. It was the sequential version. My compiler generated code 10,000 times slower than some other code running on a single core.
Needless to say, this was so utterly unacceptable that it became my full-time job for the next six months to make it better. If I recall correctly, I improved performance by a factor of 100× in the first two weeks, leaving the code a mere 100× slower than the single-core original. These were mostly stupid bugs, the sort that occur naturally in newborn compilers, but which are pretty simple to fix. I recall I got a factor of 5× by turning on optimizations in Legion, for example—literally the difference between passing -O0 and -O2 to the underlying C++ compiler. But the next 10× was more work, and the next 10× was harder still. By December of 2013, my code was only 50% slower than the sequential reference code, but I had no idea where that last 50% was hiding. I would eventually discover that I had missed a key cache-blocking optimization in the original code—which in my initial reading I had (correctly) determined made no difference to the output of the program, and thus elided, but which was essential to improving the computational intensity of the algorithm.
Meanwhile, there was another, even bigger issue. In a meeting with my advisor in February 2015, after describing everything I had done up to that point, and stating my goal of submitting to SC 2015 (with a deadline a mere two months away), my advisor informed me that nothing I had done up to that point was worthy of a paper submission. There simply wasn’t enough novelty. Building a new language wasn’t enough. Building a new compiler (in three different iterations, no less) wasn’t enough. I had to come up with something else.
Before you go knock on my advisor, note that the type system had already been published in a substantial (if not final) form, and that took quite a bit away from the novelty of what I was doing. While there were nontrivial aspects of the implementation, he was ultimately correct: what I had done up to that point wasn’t enough.
Though true, the diagnosis was also crushing. I was in my fourth year of my Ph.D. program—the time when, as Alex put it, “You wouldn’t want to get to the end of the year without having some sort of paper.” I couldn’t afford to throw everything away again.
In a state of semi-panic, I went back to my office after that meeting and immediately brainstormed every idea I could possibly think of for turning this into research-worthy work. In that process I sketched out notes for a series of optimizations, to be implemented in the compiler, that would automatically improve program performance—basically doing things that every Legion C++ programmer was forced to do, but that we really didn’t want Regent users to have to worry about.

In case you can’t read it, the document starts with the line: “I’ve been looking for things to make a paper more interesting.” Let me translate that for you: “Everything I’ve done up to this point is absolutely worthless and I’m throwing everything at the wall in an attempt to rescue my Ph.D. career.”
(You can insert the most appropriate swear word in your native language here.)
I have kept that set of notes ever since, as a reminder to myself that no matter how bleak the outlook is, you can always find ways to turn things around.
It would be easy to pretend that the next couple of months to the paper submission were easy, since I was mostly just following the plan I’d laid out in February. They were not. They were a slog, a death march to the finish line. We were constantly behind schedule, and the benchmarks we found for our experiments all turned out to be much more work then we’d expected.
Two weeks before the deadline, only one benchmark could plausibly be considered to be in reasonable shape, and we needed three for the paper. (Three is apparently a magic number determined by the gods of academic publishing as the acceptable minimum number of benchmarks for any programming language.) I had only just diagnosed the root cause of the performance problems in Pennant, and the optimizations required were well beyond what I’d be able to pull off with the compiler. The last benchmark was simply missing—we hadn’t started writing it yet.
In those last two weeks there was literally more work than one person could do, and I wouldn’t have finished it at all if I hadn’t had help. I worked furiously to revise Pennant to add cache blocking. Wonchan Lee, a new Ph.D. student in the group, wrote the last benchmark completely from scratch, and also wrote a vectorizer (another optimization) for the compiler. Really, an entire vectorizer. Also from scratch. Wonchan is awesome.
And that still wasn’t enough. One week before the deadline, we had three benchmarks working correctly, and performing well on a single node. But we had no multi-node capability whatsoever. And I had already written the paper—because it couldn’t wait—and had done so with the assumption that we would get at least basic multi-node performance working. It turned out the Legion runtime itself also had bugs. And these were bugs that neither Wonchan or I could fix: Mike Bauer was the maintainer of the Legion runtime and the only person in a position to fix any of this.
In the last week, things went down like this. On Saturday, we had zero benchmarks running on multiple nodes. Each day after that, we got one application working. On Tuesday, we had three out of three benchmarks working on multiple nodes… and zero out of three of those actually running efficiently. On Wednesday, we fixed one; Thursday, another. On Friday, Mike threw in the towel and said he wouldn’t be fixing any more bugs for us.
We ended up submitting what I thought was a weak paper. I’m pretty sure everyone in the group felt that way. When the reviews came in, everyone thought the paper would be rejected, and it felt like a chore to even write a rebuttal.
Somehow the paper got accepted. On its first submission. When every other Legion paper up to that point had been rejected at least once.
I was so overwhelmed when I got the acceptance notification that I spent an hour walking laps around NVIDIA HQ, where I was doing an internship at the time, to calm down. This was, in a very direct sense, the first concrete evidence that I could actually build a career as a researcher. Until you get there, you never really know whether you’ve got it in you or not.
Holy shit, I’d actually made it.
Yet again, it would be easy for the story to end here. Paper accepted. Yay, happy ending, right?
Ha, ha, ha, ha. Oh, boy. I wish.
It turns out that even when papers do get accepted, things can still go wrong.
Exactly one week before the camera ready deadline, I discovered that I had forgotten to validate one of the applications. (Camera ready is when the paper is supposed to be done. Like, done done. The paper is already accepted. It’s been reviewed and the reviewers all agreed that it is publication-worthy. While you can, in principle, make any changes you want prior to this final deadline, losing one entire experiment (out of a set of three) is not an acceptable change.)
I figured that it ought to be ok as long as I validated the application and confirmed the results.
Validating the application failed. The code produced the wrong answer.
At this point, all our performance results for the application got thrown out the window. If it didn’t compute the correct answer, it was meaningless how fast it ran.
In a flurry of debugging to discover the root cause of the issue, we found a fundamental flaw in the Legion runtime itself, that caused the runtime to actually execute the application code incorrectly. Regent was doing the right thing, but Legion was not. This flaw ran deep enough to make it impossible, for all intents and purposes, to fix. We were hosed.
Now, as it just so happened, Mike Bauer had been working for nearly six months at this point on an entirely new version of Legion—yet another complete rewrite. His new version promised to fix the issue we were seeing at its root. Mike had originally planned to have this new code ready in about a month, but he agreed to shoot for having a preliminary version of it ready for us to try by the end of the week.
So we bet all our hopes on getting this rewrite finished, and Mike worked furiously to get it done. But as we counted down the days, we had to face the real possibility that it wouldn’t arrive in time. And then what?
Obviously, we couldn’t publish the old numbers. That left two options. We had a version of the code that gave the correct answer, but was slow. We could use that in a new experiment, and just publish those numbers, such as they were. Or we could use the nuclear option: mail the conference organizers, apologize, and withdraw the paper from the conference.
A couple days before the deadline, we decided not to use the nuclear option, despite still not having anything. The heart of the paper’s contributions did not actually hinge on these results, even though missing them would make the paper less strong. I prepared a version of the paper worded carefully to be compatible with either option. Then, if we got the results at the last minute, I’d be able to add them, and if not I could just stick with the minimal results we had.
With less than 24 hours remaining, Mike gave the new Legion his stamp of approval and had me start testing the code. It didn’t work. For several hours, I sat with him, debugging Legion’s internal runtime logic to figure out what was going wrong.
We started debugging at 9pm. At 3am, we found the root cause. Mike and I looked at it, agreed that we were sure this really was the root cause, but that it wasn’t going to get fixed in the next 2 hours. The paper deadline was 5am.
On a whim, 90 minutes prior to the paper deadline, I went back to the last working version of the application (and the old Legion) and tried a Hail Mary. The application (in the fixed version that passed validation) was too slow because of data movement. That data movement was causing the code not to scale. So I pinned the entire working set of the application in physical memory so that the NIC would have direct access to all of it. This was massive overkill, because the vast majority of the data was private and would never need to be communicated at all. But it sidestepped the particular corner case that was causing the old version of Legion to fail.
It worked; validation succeeded. I ran all the performance experiments, went back to the paper, hurried to update the figures and double check for inconsistent text, and uploaded the final version of the paper at 4:45am, 15 minutes before the deadline.
Submission history:
Dependent Partitioning (OOPSLA 2016)
In the history of Legion, there have been a handful of cases where exploring the deficiencies of Legion has led to the discovery of a true gem. Dependent partitioning is one of those cases; the other is control replication (which I’ll cover below).
In distributed computing, it’s common to talk about partitioning data: basically, the process of splitting the data up so that it can be distributed among different memories. Legion is unusual among systems of its kind because it allows extremely general partitioning of data. Whereas it might be common for systems to allow you to chunk up data in various ways, these ways are typically limited to a fixed set of operators (like block or block cyclic distributions) that are known to be efficient. Legion on the other hand allows you to pick any partitioning whatsoever, including ones where the chosen subsets of elements are noncontinguous, or even overlapping (i.e., a single element appears in multiple subsets).
This flexible partitioning was a key ingredient of our secret sauce, but it also meant that the process of partitioning was cumbersome and error prone: users had to go and manually select the correct subsets of elements, and if they messed this up, their entire program would run incorrectly.
The deficiency in our model was obvious, but the solution space very much was not, at least to me. In the early days of us formulating a research plan to address this problem, I remember Sean offering to let me take a crack at it, and I frankly just didn’t even know where to start. As I watched him work, it became clear that he was in a completely different head space from me, despite my having been on the project several years by this point.
Sean’s key insight—which drove the rest of the design—was to distinguish between independent and dependent partitions. Independent partitions are ones that are (usually) easily computable in a straightforward way: e.g., slicing data into N equal pieces, or coloring (i.e., assigning a number to) each element and collecting subsets with each respective color. Dependent partitions are ones that are computed from other partitions. The brilliance of Sean’s scheme is that in many applications, the structure of the data itself tells you what dependent partitions you need. All the tedious, error-prone partitioning code goes away and you’re left with something simple, obvious, and (perhaps surprisingly) performant.
It would have been enough for a paper to define these new dependent partitioning operators. But Sean didn’t stop there. He created a small sublanguage for these operators and developed a type system that could prove deep, structural properties about the resulting partitions. Best of all, the fragment of logic he used was decidable, giving us a sound and complete solution—something very rare in type systems that powerful.
And of course he actually implemented the operators, showing that the new partitioning technique was not just more powerful, but also more efficient, and could even be parallelized and distributed automatically.
The paper was frankly a tour de force. And yet despite that, it went through the same rejection cycle as every other Legion paper.
Submission history:
Control Replication (SC 2017)
Remember how I said exactly one of our applications was scaling? That was still true at this point, and it was beginning to stick out like a sore thumb. The kind of code that you needed to write in Legion to actually scale was really onerous, and it was obvious to everyone involved that we needed a solution.
Newly freed from my SC 2015 submission (and not yet burdened by my discovery of the validation failure), I set about to fix this. If I recall correctly, several of us came up with more-or-less the shape of the solution independently. It might not have been obvious to anyone outside our group, but to those of us who’d had our noses shoved in it for long enough, it was pretty blatantly obvious that what we needed the compiler (or the runtime) to do was automatically transform the code in the same way we had manually done to our one application that actually scaled.
I spent a month or so hand-optimizing another application to make absolutely sure I knew what was involved. At that point, I launched into the design of the optimization itself.
In principle, the optimization isn’t that tricky. What you need to do is take a set of loops like:
for t = 0, T_final do
for i = 0, N do
some_task(...)
end
for i = 0, N do
some_other_task(...)
end
endAnd transform it into code like:
for shard = 0, num_shards do
for t = 0, T_final do
for i = N_start[shard], N_final[shard] do
some_task(...)
end
-- communicate if necessary
for i = N_start[shard], N_final[shard] do
some_other_task(...)
end
-- communicate if necessary
end
endThat is, we’re basically slicing the inner loops into “shards” and establishing a new shard loop along the outside. At that point, we split each iteration of the outer loop into its own task, and voila! the code now scales magically.
Swapping the loops around makes this look easy, but it’s worth noting what we’re really doing here. Legion’s entire premise is that it provides implicit parallelism: users don’t have to think about where the data goes or how it is communicated between nodes. But the second code sample above is explicitly parallel: the shards are now long-running tasks that explicitly communicate data between them. So when I said above that the process of manually writing one of these codes is onerous, that was an understatement, because it sacrifices one of Legion’s most fundamental tenets in the name of performance.
Control replication is quite literally the optimization that saved Legion. If we hadn’t made it work, we would have lost the essence of the project.
Getting back to the implementation, the loop transformation is the easy part. The hard part is figuring out what data needs to go where.
This turns out to be one of the fundamentally intractable problems of computer science. The problem is taking a data structure like a mesh, say this one:
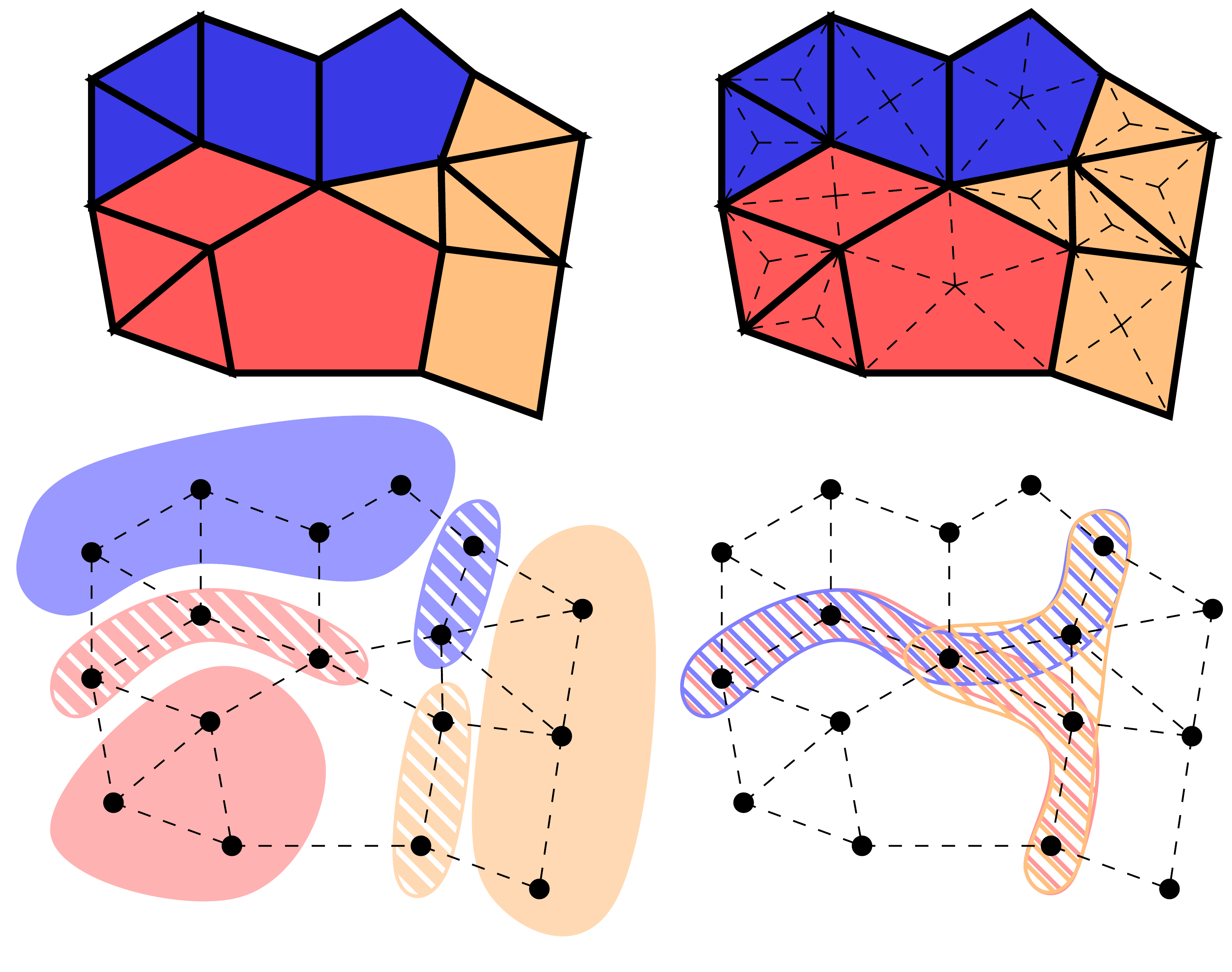
And figuring out which of these various solid or hashed regions are required at each point in the computation. Except we need to do this in the compiler, which doesn’t know: (a) how many pieces of the mesh there are, or (b) the Venn-diagram overlaps of the various pieces. All we see are symbolic references to entire subsets of this mesh, like zones_private[i] would refer to the ith piece of mesh shown in the upper left corner.
As it turns out, this problem is tractable to solve in Regent because the language has first-class constructs that represent exactly the pieces of the data that we need. (If you read my notes from earlier closely enough, you’ll note that the same basic insight drove certain language changes that enabled other optimizations in the SC 2015 paper. But I hadn’t fully internalized what it meant at the time.)
Even then, I had to go design an entire new intermediate representation (what the compiler uses to represent code) and compiler analysis for region data movement in programs. I was fortunate to do an internship with NVIDIA Research in the summer of 2015, and I convinced them to let me spend it building the optimization, which meant that I got to sit near Mike again while designing the IR—a key benefit since it turns out that many of the algorithms are similar between the compiler IR construction and runtime dependence analysis. Work continued into the fall after returning to Stanford. To my surprise, once I got all the pieces into place, everything basically worked.
By this point you may have noticed a pattern that nothing ever really goes to plan, even when it’s going “well.” That was certainly the case for this paper.
We planned to submit to SC 2016. Around December of 2015, I remember sitting at a lunch with my advisor and some guests where we talked about the work we were doing, and Alex made a comment to the effect of (paraphrased): “Well, we’d have to really mess up the submission to not get accepted.”
You see, an early version of the optimization was already working at this point, and the preliminary results were amazing. In my entire career, I’d never seen results so good. The optimization had rough edges, corner cases it couldn’t handle, but when it worked, the performance was astonishing: nearly ideal weak scaling out to 512 nodes, where our previous (unoptimized) results were falling over at about 16 nodes.
Of course those pesky corner cases ended up being a royal pain to solve.
Two months before the deadline, I ramped up my effort to 10 hours a day, 5 days a week, to be sure I got my experiments done in time. One month before the deadline, I increased that to 12 hours a day, 5 days a week. Two weeks before the deadline, I started working 16 hour days, 6 days a week. In the last week, I just worked 16 hours every day.
In the end I was so wrung out that despite the fact that the empirical results were literally perfect, so perfect you couldn’t ask for anything better, I still couldn’t write the paper. I tried anyway, but it was one of the most frustrating writing experiences I’ve ever had, and when I finally passed the first draft to my advisor, he described it as “incomprehensible.” Hint: when your own advisor can’t make heads or tails of what you’ve written, you’re in deep trouble. We did what we could but there was so little time before the deadline that there just wasn’t much we could do.
I submitted anyway, but I remember it being one of the most palpable sensations of professional failure I’ve ever experienced, even worse than the “oh shit” moments with the 2015 paper. I was almost worried the paper would be accepted in its current form, because the empirical results were so outstanding, and then I’d have this incomprehensible paper on my record that I wouldn’t be able to properly fix before its camera ready deadline. (If that seems implausible, remember that the SC 2015 paper was in fact accepted on its first submission.)
But in the end I didn’t need to worry about that, and the paper would be rejected three times before finally finding a home.
In retrospect, the problem with the early versions of this paper was that I wrote the paper in exactly the way I had written the compiler. I had created this entirely new IR which I wanted to be the centerpiece of the paper. The problem was that no one understood it, or its implications, or why any of it was even necessary in the first place. In addition to that, I hadn’t fully internalized some of the realizations I mentioned above about why this problem was even possible to solve at all, and so the introduction simply failed to communicate what we’d done.
Lesson learned: if you can’t communicate your results, it doesn’t matter how spectacular they are.
Over the course of the next three submissions, I progressively refined the narrative of the paper until I finally threw in the towel with the last submission and just ditched the novel IR altogether. I discovered that the optimization could be performed with mostly-standard compiler technologies, so that’s how I wrote the paper, even though it bears very little resemblance to how any of it is actually implemented.
Submission history:
- SC 2016: rejected. Source.
- PPoPP 2017: rejected. Source.
- PLDI 2017: rejected. Source.
- SC 2017: accepted. Source, PDF.
Tracing (SC 2018)
The entire point of the control replication paper was to improve performance. But it turned out that control replication only really improved performance along one axis: scale-out performance. Control replication allows you to take an application, and keep scaling it indefinitely, as long as the problem size increases proportionally to fill the machine. In HPC we call this weak scaling. If instead you try to do strong scaling, where the problem size is fixed, then as you scale out you have less work to do on each node. Less work takes less time, and pretty soon, if your system has any overheads at all, those start to be really noticeable.
The problem was that Legion had some pretty high overheads.
At this point, Mike, Sean and I all had our hands full in our respective corners of the project, and none of us had the bandwidth to fix this. Wonchan, who had by this point contributed not just vectorization, but also a GPU code generator to Regent, took on the work to address overheads in Legion itself.
The basic idea is straightforward: many applications end up doing the same thing over and over again. In this case, it’s pretty pointless to keep doing work when we know the outcome will be the same. So we can save a lot of work by capturing a trace of what we did the first time around, and then replaying it.
This idea is as old as dirt in computer science, but again, what makes it tricky is applying it to a distributed computing setting where you have to reason about different pieces of data flowing around the system (remember the mesh diagram I showed earlier).
Following our classic Legion pattern, we submitted to PLDI first, got rejected, then sent the paper to SC.
Submission history:
Automatic Parallelism (SC 2019)
Automatic parallelism is one of those ideas that’s been beaten to death in HPC. For various reasons regarding certain application codes we were committed to supporting, we decided to build it anyway. This was work again done by Wonchan, but this time on top of Regent instead of Legion.
The problem with this paper was therefore in figuring out if we’d actually done anything novel. The work was done—there was no question we were going to support it. But was there anything interesting about the way we’d done it?
As it turned out, the answer was yes. And the key idea goes back to what I was saying before about realizing the full implications of partitioning. Strictly speaking, partitioning is about dividing up the data. But we realized that you can also talk about partitioning the space of loop iterations. And when you have a piece of code like, say:
for elt in mesh do
mesh[elt].x += mesh[mesh[elt].neighbor].y
endWe can determine, by analyzing this code, that we need a copy of each mesh element’s neighbor to perform this calculation. This is, in essence, a constraint on the valid partitionings of the mesh that would be safe to use in this program. By solving these constraints, we arrive at a set of valid partitionings. And dependent partitioning provides exactly the operators we need to do that—something that is often challenging in competing approaches.
Wonchan really nailed this paper and it sailed through on its first submission. I was especially pleased to see the paper get nominated for best paper, though unfortunately we didn’t win the award.
Submission history:
Pygion (PAW-ATM 2019)
This paper makes me unreasonably happy.
It is a paper that does everything “wrong.” During my Ph.D. training, I was taught to not submit to workshops. If anything was worth doing, it was worth doing well. And if it was worth doing well, you might as well try to get full credit for doing it, and submit to top-tier conferences. That was an approach I took to every other paper submission, sometimes insisting on continuing to submit to first-tier conferences long after my other collaborators had begun to waffle. But this paper I never even attempted to submit to a conference.
The paper concerns work that I honestly thought would never be published. At its most basic, Pygion is “just” a set of Python bindings over Legion. It was something I built because users needed it, not because I thought it was research-worthy at the time.
And unlike every other Legion paper ever written, the paper makes no pretense to generality whatsoever. Research venues are more interested in publishing results that are widely applicable—the more general, the better. But as a team creating a new programming system from scratch, this created a tension: the more we took full advantage of Legion’s unique features, the higher the risk that reviewers might complain that our techniques wouldn’t apply to any other system. This ended up being one of the more common reasons our papers got rejected. And so as a rule we tried to generalize our results as much as possible—a process that resulted in true gems like the “Dependent Partitioning” paper, but a process that also sometimes ironically diverted energy from actually pushing the results themselves forward.
This is the first paper where I got to say exactly what I wanted, exactly how I wanted to, without having to pander to the sensibilities of top-tier conference reviewers.
The paper is pretty simple. I had written a language called Regent, published in SC 2015. Regent does a lot of great stuff because it has a static type system that directly embodies the Legion programming model—and thus the compiler can figure out all the optimizations required to get excellent performance out of the system. The idea here was to see how far we could get with Python. Would it be possible at all? Or would performance suffer so much that it wouldn’t provide a meaningful replacement?
To my surprise, the answer was that it works and actually gets excellent performance (with some qualifiers). The syntax is a bit hacky, but through the magic of dynamic typing, and just enough runtime analysis of the program, we can recover most of the important optimizations that Regent would normally do. There are obviously limits to this approach—there is no whole program analysis, so truly global optimizations would be impossible. But we got far enough to take the classic suite of Regent benchmarks, rewrite the core logic in Python, and achieve the same weak scaling performance and scalability as the original codes.
Submission history:
- PAW-ATM 2019: accept. PDF.
Task Bench (SC 2020)
This paper is very different from the others on this list. Almost everything else here is a technology paper, describing some fundamental innovation in some part of the system: either the language, or compiler, or runtime, etc. Task Bench was the first time I’d worked on a benchmark code.
The idea was suggested to me by way of our colleague George Bosilca. George had had a student develop a benchmark which he’d used to compare some different systems. The paper had been rejected, and George had mentioned to Alex that he thought it would be worth working on an improved version of this benchmark. Alex came to me and suggested that if I was interested, he could hire some summer students to work on the implementations with me. Basically he reasoned that if we wanted to target N systems with M different application patterns, we’d have the students write N×M codes.
Initially I was skeptical. The benchmark didn’t seem that interesting, and I wasn’t sure what we would learn (or whether it would be publishable).
There were two things that convinced me to go for it.
First, the issue of overheads in Legion was still nagging at me. I was facing internal resistance from some members of the team who said that the overheads were low enough, or at least acceptable given what Legion was doing. But were they really? Part of the problem here was that there was no way to compare, so I couldn’t go back and prove to anyone that the problem was real.
Second, as I thought about the problem, I realized that there was a way to finish this project in N+M effort instead of N×M. Basically, by building a framework to describe what was being executed, we could write in each system a code that would just run the pattern as efficiently as possible. If we did our job right, we’d write N programs, and then code up M patterns, but we wouldn’t need to write the full N×M by hand.
We hired 5 summer students through Stanford, and my collaborator Wei Wu hired another student at Los Alamos. George provided one of his students to help out as well. So between all of us, we had 7 people actively writing codes that summer, and we managed to finish implementations of 15 distributed programming systems.
Finishing the implementations is one thing, making sure they’re efficient is something else. Unless we were sure that we’d done our due diligence in optimizing each implementation to its fullest extent, the results wouldn’t really be representative, and worse, we’d probably offend someone in the process.
So, to be sure that we were really doing things properly, we reached out to the developers of each of the 15 systems, and solicited feedback on our approach. It took some prodding in a couple of cases, but we ultimately got in contact with at least one member of each project, and in several cases the developers were highly engaged in helping us optimize the codes.
That still left the problem of analyzing and presenting the results. I now had a tool capable of running an arbitrary number of application patterns on each of these 15 different systems. But what should I actually measure?
One thing I realized while working on this paper is that “overhead,” though it seems intuitive, is actually a slippery concept. One way to measure overhead is to run a bunch of empty tasks through the system. Empty tasks take no time, so anything left at that point is, by definition, overhead. But what are you actually measuring? Some systems reserve exactly one core for doing scheduling. Some systems schedule on every core. On some systems, this is configurable, and then how do you pick the number of scheduling cores to use?
I realized the only sane way to do this is to measure performance under some load. That is, the system has to do some amount of useful work. Suppose we set a goal of hitting 50% of the peak FLOPS of the system. Then it’s obvious that you can’t use 100% of your cores to schedule, at least not full-time, because then you would do no useful work. Thus, the useful work requirement provides us a way of keeping the systems honest, while also allowing them to use whatever settings happen to perform best for a given system.
This led to some interesting new terminology, the minimum effective task granularity (METG), which captures the smallest task you can run while achieving at least a stated level of performance. You can think of it as being like an “honest overhead” measurement, because you are forcing the system to still do useful work, while getting through as many tasks as possible (and thereby minimizing the overhead). While it wasn’t originally the expected contribution of the paper, it’s probably my favorite part, and something that I hope takes off.
But this paper also had its share of issues. Reviewers didn’t understand what it meant to implement a “task” on systems that didn’t have tasks. The concept of METG was tricky and easy to misunderstand. Although we refined the paper with each submission, it still wasn’t enough, and after three failed submissions some of our collaborators were inclined to give up and take the paper to a second-tier conference. But I wasn’t ready to give up, and on the paper’s fourth submission, we made it through.
Despite the tribulations this paper went through, it is probably the one with the least evolution from the initial to the final submissions. The initial submission had it basically right, we just had to polish it over and over to get the narrative smooth enough that reviewers grasped what we were doing.
Submission history:
- SC 2019: rejected. Source.
- PPoPP 2020: rejected. Source.
- PLDI 2020: rejected. Source.
- SC 2020: accepted. Source, PDF.
Dynamic Control Replication (PPoPP 2021)
While Legion began as a research project, it was never our goal for it to remain purely in the academic realm: we really wanted to produce a piece of software that would last and that people would actually use. That meant, in part, transforming the research culture of the core project into an engineering culture. By 2017, when the work on dynamic control replication began in earnest, that transformation was already underway: we had moved from occasional “throw it over the fence” public software releases, to doing everything in the open. We now had a real continuous integration (CI) infrastructure, instead of relying on me to manually hand-test everything. As far as the software itself, we cared much more about production quality and paying down technical debt from the very beginning, as opposed to building the software quick and dirty and paying the debt over time. And it meant that we would build things that were important, even if there was no immediate paper payoff—though we certainly hoped to publish the pieces that were interesting enough to warrant it.
Dynamic control replication (DCR) was, at some level, just the dynamic version of the optimization that I had previously published in SC 2017. Dynamic in this case meant that it was built directly into the runtime system, instead of into the compiler. There were a couple reasons we decided to do this:
- We wanted to be able to provide CR from other languages beside Regent: C++, Python, etc. Again, in a pure research project, we wouldn’t have cared. But we wanted people to actually use this, and it was clear that there would never be a world in which everyone using Legion would be doing it through Regent. CR was turning out to be such a profoundly important optimization that we simply couldn’t ignore it.
- Being a runtime system meant that Legion had access to dynamic information, and therefore could potentially optimize programs inaccessible to the static version of the optimization. As I mentioned before, the compiler would always be inherently limited by these fundamentally challenging program analysis problems, that made it impossible to optimize many classes of programs.
- The original SCR (static CR) was written as research software, at a level of quality consistent with that goal. Remember the brand new IR I invented? Yeah, it turned out to be a huge source of bugs. And so part of the goal of DCR was just to do it right, with all the best engineering practices up front.
With basically zero uptake of CR in the rest of the programming system world, the odds of getting scooped were essentially nil, and thus we could afford to take our time, do the optimization properly, and publish when it was ready. But that was a cherry on top at this point.
Along the way to building DCR, Mike (who was still the exclusive owner of all Legion runtime code) discovered that there were other, even more foundational changes we would need to make. But those would end up turning into an entirely separate paper.
The interesting thing about this paper is that we wrote, finished, and deployed the optimization into production before even thinking about writing the paper on this one. When Mike began to organize the effort to write the paper, DCR had already been the de facto production version of Legion for over a year, and he solicited everyone on the team to submit the experiments they wanted included in the paper. Compared to our previous papers, it was striking how orderly of a process this was. There was no frantic rush, no endless stream of showstopping bugs, and no last-minute catastrophic discoveries. One of the reasons why this paper has so many experiments is that basically everyone had it already working as their daily driver, so it was easy to gather a lot of data.
After the struggle to communicate the value of SCR, Mike knew exactly how to write the paper on this one and it sailed through on its first submission.
(Note: from this point onward, our paper submissions moved to Overleaf, so the submission sources are not publicly available.)
Submission history:
- PPoPP 2021: accepted. PDF.
Index Launches (SC 2021)
This is a paper that I thought truly would never be published, and yet ironically got accepted on its first submission.
Index launches had been a part of Legion since very early in the project. The basic idea is that if you’re going to a launch a bunch of tasks like:
for i = 0, N do
my_task(some_data_partition[i])
endThere should be a way to rewrite the entire loop as a single operation. Regent has no syntax for this, so I can’t give you actual code here, but conceptually it’s something like the following (using Python pseudocode):
IndexLaunch(my_task, [0, N], some_data_partition, lambda i: i)Because we can suck the entire loop into one operation, we can reduce a bunch of analysis costs from 𝒪(N) to 𝒪(1) or at least 𝒪(log N).
It’s a nice, clean, simple idea, and it’s also key to almost everything Legion does. For example, the spectacular success of DCR is only possible because index launches gave us a compact representation of the program (something that we argue in this paper).
For a paper, the idea was perhaps too simple. It was also just old. This was literally one of the first features that Mike and Sean came up with in the very early days of Legion, when I was still a neophyte researcher, and it had been present in every version of Legion publicly released.
And yet, index launches had never been properly described in any published research paper. They only got a passing mention in my SC 2015 paper, where I talk about an optimization Regent does to take advantage of this feature of the Legion runtime.
But, having worked recently on the Task Bench paper that made it into SC 2020, I was in a unique position to look around at the ecosystem to see what other projects were doing. After all, I had just led a team to develop efficient implementations of Task Bench in 15 different systems. And after doing that research, I realized that literally no one in the field was using this idea, except us. We’d been yammering at people about this for nearly 10 years, and no one had listened.
That was the point where I decided I wanted to make this a paper, if at all possible.
I pitched the idea to Rupanshu Soi, an undergraduate student in India who had joined the project initially as an open source contributor, and whose work I’d been advising. This was the perfect paper for Rupanshu to take on, since he was already actively working on improvements to Regent’s index launch optimization. I didn’t see any way to get that work published unless it was merged into a larger paper of some sort. Meanwhile, after sitting idle for nearly ten years, it was obvious that if writing this paper fell to myself or the other original contributors, it simply was never going to happen. The energy to push it over the finish line had to come from someone new.
But given that index launches had already been a feature of Legion for so long, we had to think carefully about what the contribution of the paper would actually be. After some discussion, we settled on a three pronged plan:
- Think carefully about the design space of ideas already present in the literature, and how index launches relate to them. Not entirely surprisingly (since no one had copied us in all this time), we were able to show that we made different tradeoffs with different benefits from other approaches.
- Demonstrate that the spectacular results presented in the DCR paper really couldn’t have been achieved without index launches. You need both to make programs really scale. Thus index launches are a sort of enabling technology that you need to make a DCR-based runtime work.
- Show some other nice improvements to index launches, by for example adding an optional hybrid analysis to make the Regent compiler’s optimization more complete.
This was also my first paper as an advisor (i.e., in the last author slot of the paper instead of the first or Nth). Rupanshu did a great job on this one and it got accepted on the first submission.
Submission history:
- SC 2021: accepted. PDF.
Visibility Algorithms (PPoPP 2023)
At its core, Legion has a deceptively simple premise: you can partition a distributed data structure any way you want, any number of times, with arbitrary hierarchy. This has turned out to be the single most powerful and also the single most challenging feature of the system, with implications that took us most of a decade to fully understand.
As our understanding evolved, so did the Legion implementation. And so, by 2021, we had iterated through three major versions of a certain core Legion algorithm: the algorithm that figures out what version of a piece of data a given task should have access to.
This was basically a paper waiting to happen. We had this very deep insight into how these systems work, on the basis of developing progressively refined implementations. Mike in particular thought he knew how to write a paper about it. But the challenge was that we’d developed the software over a period of multiple years. Was it even possible to run a set of applications on versions of Legion separated by so much time, let alone do experiments that allowed head-to-head comparison?
So after stepping off the index launch paper, with experiments fresh on my mind, I set about to see if it was possible to do this. The core insight that I had was that it might be possible to swap out only one box in the architecture stack diagram: Legion itself. That is, could I use an up-to-date Regent (the language), and an up-to-date Realm (the low-level portability layer), and somehow shove in the (many years) old versions of Legion into the middle?
After a couple of days of furious Git hackery and papering over API differences, I had what I wanted. Brand new Regent, brand new Realm, and three different versions of Legion sitting in the middle. And the best part was, the applications mostly didn’t need to know that anything had happened. To the extent that there were compatibility hacks I needed to put in, they went into either the API shims or the compiler.
With that done, I ran all the experiments, and handed the results off to Mike to write the paper itself. The tricky part was figuring out how to communicate what we’d actually done. Because Legion is such a different system than many of the ones that share the “task-based” moniker with us, most reviewers come in with the wrong expectations about what we’re setting up to do. This caught us in multiple submissions of this paper until we polished the story enough to make sure people got it.
Submission history:
- PLDI 2022: rejected.
- SPAA 2022: rejected.
- PPoPP 2023: accepted. PDF.
Reflections
When I back up and look at all the work we’ve done over the last 12 years and change, despite all the ups and downs and moments of sheer existential terror, the biggest thing I have to say is that I’m really proud. We did a lot of great work. Not only did we push forward the frontier of HPC, but we did so while building a great piece of software and somehow managing to distill and communicate many important conceptual contributions of the work we were developing. I’m aware of projects that have done one or the other, but I’m not aware of many projects that managed to do both. In part that’s because the problems ended up being much deeper than anyone expected, giving us a lot to work on both in research and engineering.
I never would have expected, when we started the Legion project in 2011, that we would still be discovering core technological contributions in 2023. And yet, that has continued to be the case. As recently as the latter half of 2023, we’ve made substantial refinements in our algorithms that are critical to running at extreme scales—allowing us to run, as of only a few months ago, on the full scale of Frontier, the current #1 supercomputer.
From a people perspective, the reason all this worked out is because we kept the core contributors actively engaged post-graduation. Mike Bauer graduated in 2014 but continues to be the main (and usually sole) developer of Legion. (We are making a concerted effort to increase that bus number. Really, honest.) Sean Treichler graduated in 2016 but continued to work actively on Realm until fairly recently, and still helps out (albeit in a much reduced role). I graduated in 2017 and am still continuing in my various and sundry roles, including beating on our software when the circumstances require. And there have been many other people involved over the years, a surprising number of whom have continued to work on Legion in some capacity post-graduation.
From an academic perspective, as I have said, there were far more problems to solve in this space than any of us anticipated. I haven’t even covered all the papers here; there are more to be found on Legion’s publications page, but someone else will have to tell those stories.
From an engineering perspective, I think we managed to build the right kind of culture at the right time for the phase of the project we were in. In the beginning, I was our test suite and our CI. As the project grew and we needed something more rigorous, we evolved the approach to grow with us, adding more and more sophisticated tests as we went along. There is more to do, as some of our users on the bleeding edge unfortunately know all too well, but overall the level of completeness and robustness of our tests is dramatically better than it was.
From a product perspective, we now have a killer app, a product that NVIDIA now employs a nontrivial number of people to develop, which is built on Legion, and serves in part to justify ongoing investments in the project. And this is one of several areas where we now have compelling products available.
Of course, all of this has only been possible because we had great leadership who kept us on track all along the way. It’s not easy managing a project that spans the gamut from academic to engineering, but Alex and Pat did it.
If there’s one thing I want to reiterate, it’s that this is one, small slice of what has happened in the project, and couldn’t possibly cover every contribution or every contributor. And even in the events I’ve described, this is only one perspective. Hopefully with time we’ll get to hear from others involved in the project as well.